Every day, three times per second, we produce the equivalent of the amount of data that the Library of Congress has in its entire print collection, right? But most of it is like cat videos on YouTube or 13-year-olds exchanging text messages about the next Twilight movie.– Nate Silver
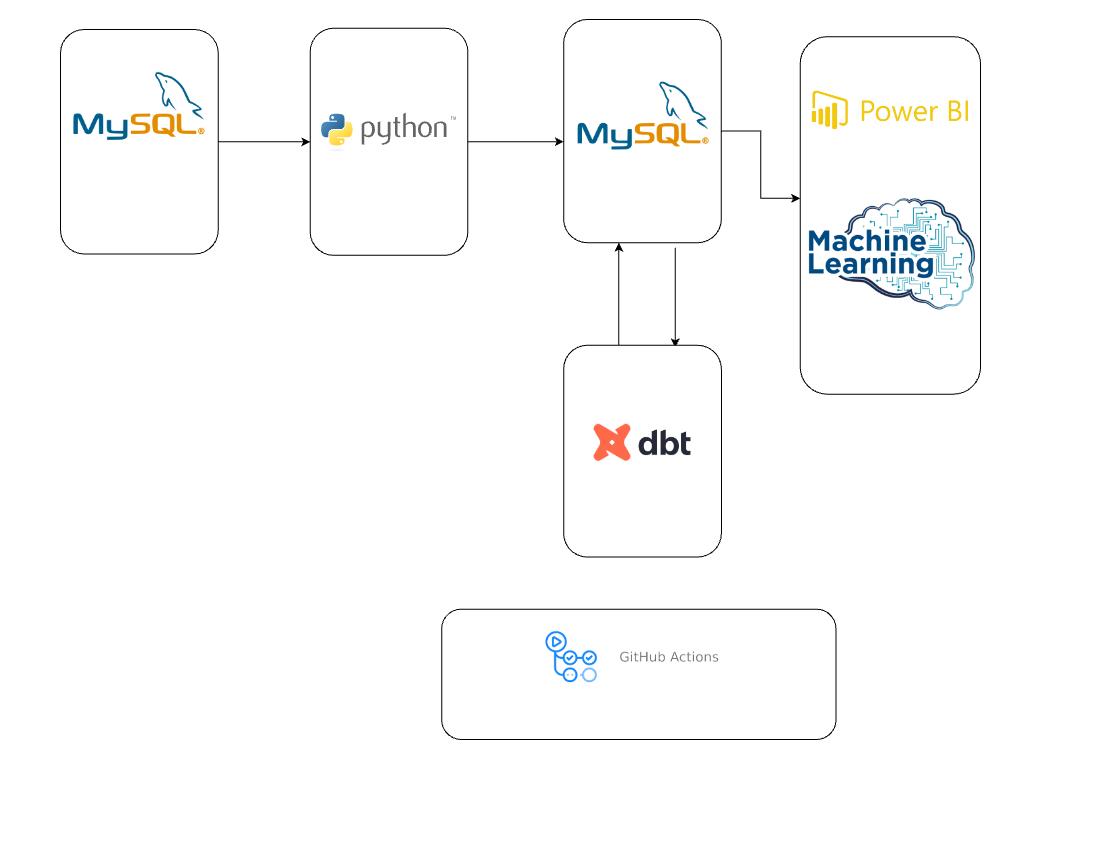
Building a Robust Credit Scoring Data Platform: A Dive into MySQL, Python, dbt, Power BI, and Docker
In today's data-driven world, businesses thrive on insights derived from robust data pipelines. Whether it's understanding customer behavior, optimizing operations, or making strategic decisions, having a solid foundation for data analysis is paramount. One such foundation is a credit scoring data platform, which not only aids in risk assessment but also provides invaluable insights into customer behavior and financial trends.
Check out the complete project on GitHub
Understanding the Components
MySQL: As the primary data source, our production MySQL database houses a wealth of valuable information. From transactional data to customer demographics, this database serves as the starting point for our data journey.
Python: Python emerges as the language of choice for writing our Extract, Transform, Load (ETL) processes. Leveraging its versatility and rich ecosystem of libraries, we craft robust scripts to extract data from the production MySQL database, apply necessary transformations, and load it into our MySQL data warehouse seamlessly.
dbt (data build tool): Central to our data modeling efforts, dbt empowers us to define, document, and test data transformation pipelines with ease. With dbt, we can build modular, version-controlled models that transform raw data into curated datasets, ready for analysis. Its ability to automate SQL-based transformations streamlines our workflow, ensuring consistency and reliability in our data modeling endeavors.
Power BI: Visualization is key to unlocking the insights hidden within our data. Power BI serves as our visualization tool of choice, offering a user-friendly interface and powerful analytical capabilities. With its intuitive drag-and-drop features and robust dashboarding capabilities, Power BI enables us to create compelling visualizations that convey complex insights at a glance.
Docker: Docker simplifies the process of setting up and managing our development and production environments. By containerizing our services, we ensure consistency across different stages of development and deployment, reducing the "it works on my machine" problem.
Setting Up Docker Services
To orchestrate our services, we use Docker Compose. Here’s the docker-compose.yml file that sets up our MySQL databases, Python scripts, and dbt:
version: '3.8'
services:
mysql-production:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: loans_db
ports:
- "3307:3306"
volumes:
- mysql-data:/var/lib/mysql
mysql-warehouse:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: loans_warehouse
ports:
- "3306:3306"
volumes:
- mysql-warehouse-data:/var/lib/mysql
generate-data:
build:
context: .
dockerfile: Dockerfile_generate_data
environment:
MYSQL_PROD_HOST: mysql-production
MYSQL_PROD_PORT: 3306
MYSQL_PROD_USER: root
MYSQL_PROD_PASSWORD: password
MYSQL_PROD_DB: loans_db
depends_on:
- mysql-production
etl-script:
build:
context: .
dockerfile: Dockerfile_etl_script
environment:
MYSQL_PROD_HOST: mysql-production
MYSQL_PROD_PORT: 3306
MYSQL_PROD_USER: root
MYSQL_PROD_PASSWORD: password
MYSQL_PROD_DB: loans_db
MYSQL_WAREHOUSE_HOST: mysql-warehouse
MYSQL_WAREHOUSE_PORT: 3306
MYSQL_WAREHOUSE_USER: root
MYSQL_WAREHOUSE_PASSWORD: password
MYSQL_WAREHOUSE_DB: loans_warehouse
depends_on:
- mysql-production
- mysql-warehouse
dbt:
build:
context: .
dockerfile: Dockerfile_dbt
environment:
DBT_PROFILES_DIR: /usr/app/dbt
depends_on:
- mysql-warehouse
volumes:
mysql-data:
mysql-warehouse-data:Dockerfiles for the Services
Dockerfile for Data Generation (Dockerfile_generate_data):
FROM python:3.9-slim
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY generate_data.py .
CMD ["python", "./generate_data.py"]Dockerfile for ETL Script (Dockerfile_etl_script):
FROM python:3.9-slim
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY etl_script.py .
CMD ["python", "./etl_script.py"]Dockerfile for dbt (Dockerfile_dbt):
FROM fishtownanalytics/dbt:latest
WORKDIR /usr/app
COPY dbt/ ./dbt/
CMD ["dbt", "run"]Data Extraction with Python
Once we've set up our Docker services, we can start by extracting data from the production MySQL database using Python scripts. Below is a sample Python script for data extraction:
import mysql.connector
# Establishing connection to the MySQL database
def connect_to_mysql(host, port, user, password, database):
connection = mysql.connector.connect(
host=host,
port=port,
user=user,
password=password,
database=database
)
return connection
# Sample data extraction function
def extract_data(connection):
cursor = connection.cursor()
# Your data extraction logic here
cursor.close()
connection.close()
if __name__ == "__main__":
# Replace these values with your MySQL connection details
host = "mysql-production"
port = 3306
user = "root"
password = "password"
database = "loans_db"
connection = connect_to_mysql(host, port, user, password, database)
extract_data(connection)Transforming Data with dbt
Once extracted, the data undergoes a series of transformations orchestrated through dbt. Leveraging SQL-based transformations, we cleanse, enrich, and model the data to create a unified view of customer information—a golden record that serves as the foundation for our credit scoring endeavors.
To define the transformation pipelines, we create models using dbt. Below is an example of a dbt model for creating a customer dimension table:
-- models/dim_customer.sql
SELECT
CustomerID,
Name,
Address,
ContactInfo
FROM ;Data Visualization with Power BI
With our curated datasets in place, we leverage Power BI to create insightful visualizations and dashboards. From interactive charts depicting credit utilization trends to predictive models forecasting default probabilities, Power BI empowers us to explore the data from various angles, enabling stakeholders to make informed decisions with confidence.
Below is a snippet of the Power BI dashboard showcasing key metrics related to loan performance:
Conclusion
The culmination of our efforts results in a powerful credit scoring data platform that not only facilitates risk assessment but also empowers stakeholders with actionable insights. By harnessing the combined capabilities of MySQL, Python, dbt, Power BI, and Docker, we've created a robust data pipeline capable of transforming raw data into strategic assets.
Beyond credit scoring, our platform lays the groundwork for a wide array of analytical endeavors—from customer segmentation to trend analysis—fueling innovation and driving business growth.
In the dynamic landscape of data analytics, building a resilient data pipeline is essential for deriving actionable insights and driving informed decision-making. By harnessing the power of MySQL, Python, dbt, Power BI, and Docker, we've constructed a credit scoring data platform that not only meets the needs of today but also lays the foundation for future innovation.
As businesses continue to navigate the complexities of the digital age, having a solid data infrastructure becomes increasingly critical. With the right tools and methodologies in place, organizations can unlock the full potential of their data, gaining a competitive edge in an ever-evolving market landscape.
Toptal skill reference:Data modeling analyst
Toptal skill reference:Data engineer